Hadoop Installation Guide
Windows 10/11 - Apache Hadoop 3.2.4 with Java 8
Installation time: 30-45 minutes
Important Prerequisites
- Windows 10 or Windows 11 operating system
- Administrator access to your computer
- Stable internet connection
- Minimum 2GB free disk space
- Hadoop HDFS only supports Java version 8
Instructions:
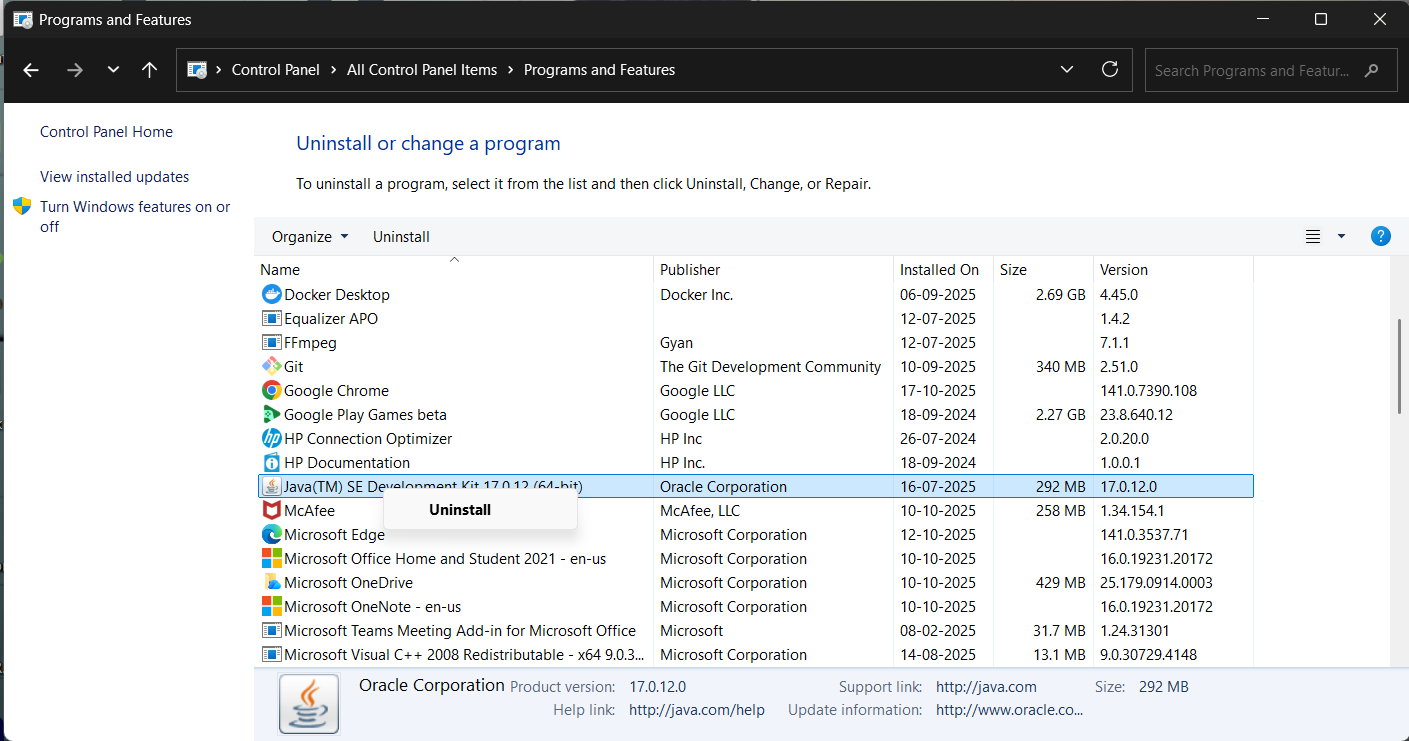
- 1Click Start Menu and search for Control Panel
- 2Select View by: Category
- 3Navigate to Programs → Programs and Features
- 4Find and right-click Java package, select Uninstall
- 5Wait for completion and close the window
Key Ports Reference
HDFS NameNode
localhost:9870
YARN ResourceManager
localhost:8088
Hadoop Configuration
localhost:9000
File Locations
Java JDK
C:\Program Files\Java\jdk1.8.0_411
Hadoop
C:\hadoop
Hadoop bin
C:\hadoop\bin
Hadoop sbin
C:\hadoop\sbin
Installation Complete!
Your Hadoop 3.2.4 cluster with Java 8 is now ready for development and testing of big data processing applications.
If you encounter any errors during installation, please contact us for support.
What's Next?
With Hadoop installed, explore big data workflows and tools:
Common Use Cases
📊 Big Data Processing
Process massive datasets with MapReduce, analyze logs, and perform batch data transformations across distributed systems.
🔍 Data Analytics & Mining
Run complex analytics queries on terabytes of data, generate reports, and extract insights from unstructured information.
🎓 Learning Distributed Systems
Master distributed computing concepts, practice MapReduce programming, and understand HDFS architecture hands-on.
💼 Data Warehousing
Store and manage large-scale data warehouses, integrate with Hive and Spark, and build ETL pipelines for business intelligence.
🛠️ Hadoop Ecosystem & Essential Tools
Data Processing
- •Apache Spark - Fast cluster computing engine
- •Apache Hive - Data warehouse software
- •Apache Pig - High-level data flow platform
- •Apache Flink - Stream processing framework
Data Storage & Management
- •Apache HBase - NoSQL database on HDFS
- •Apache Cassandra - Distributed database
- •Apache Kafka - Distributed streaming platform
- •Apache Sqoop - Data transfer tool
Monitoring & Management
- •Apache Ambari - Cluster management platform
- •Cloudera Manager - Enterprise management
- •Apache Zookeeper - Coordination service
- •Ganglia - Monitoring system
🚀 Performance Optimization & Configuration
HDFS Configuration
- •Adjust block size for optimal performance (default 128MB)
- •Configure replication factor based on cluster size
- •Set appropriate heap sizes for NameNode and DataNode
- •Enable compression for network and storage efficiency
- •Configure data locality for faster processing
YARN Resource Management
- •Allocate memory and CPU resources efficiently
- •Configure container sizes for optimal job execution
- •Set up resource queues for different workloads
- •Enable preemption for better resource utilization
- •Monitor application logs and resource usage
🔧 Troubleshooting Common Issues
❌ "Java is not recognized" or Java version conflicts
Solution: Ensure Java 8 is properly installed and JAVA_HOME points to the correct JDK directory. Remove other Java versions and verify PATH variables.
echo %JAVA_HOME% && java -version⚠️ "Permission denied" or "Access is denied" errors
Solution: Run Command Prompt as Administrator, check file permissions, and ensure antivirus software isn't blocking Hadoop processes.
Right-click Command Prompt → Run as administrator🔄 Services fail to start or "Connection refused" errors
Solution: Check if ports 9000, 9870, 8088 are available. Format NameNode again if corrupted. Verify firewall settings and network configuration.
netstat -an | findstr :9870💾 "Out of memory" or heap space errors
Solution: Increase heap size in hadoop-env.cmd file, close unnecessary applications, and ensure sufficient system RAM (minimum 4GB recommended).
set HADOOP_HEAPSIZE=2048🔒 Security & Best Practices
Security Configuration
- •Enable Kerberos authentication for production clusters
- •Configure SSL/TLS encryption for data in transit
- •Set up proper file permissions and access controls
- •Use Apache Ranger for fine-grained access policies
- •Enable audit logging for compliance requirements
Operational Best Practices
- •Regular backup of NameNode metadata and configuration
- •Monitor cluster health and disk usage continuously
- •Implement proper data retention and archival policies
- •Use version control for configuration files
- •Plan for disaster recovery and high availability
📖 Learning Resources
Official Documentation
Tutorials & Courses
💡 Pro Tip: Always stop Hadoop services using stop-all.cmd before shutting down to prevent HDFS corruption.
🏗️ Advanced Hadoop Architecture & Distributed Computing Mastery
Master the intricacies of Hadoop's distributed architecture, understand HDFS internals, YARN resource management, and advanced MapReduce programming patterns. This comprehensive guide covers enterprise-grade Hadoop deployments, performance tuning, and ecosystem integration.
🗄️HDFS Architecture Deep Dive
Hadoop Distributed File System (HDFS) is designed to store very large files across machines in a large cluster. Understanding its architecture is crucial for optimizing data storage, retrieval, and processing performance in big data environments.
NameNode (Master)
- Maintains file system namespace and metadata
- Stores block locations and file permissions
- Handles client requests for file operations
- Manages DataNode heartbeats and block reports
- Coordinates block replication and recovery
DataNode (Workers)
- Store actual data blocks on local disks
- Send periodic heartbeats to NameNode
- Perform block creation, deletion, and replication
- Serve read and write requests from clients
- Execute block recovery operations
HDFS Block Management & Replication Strategy
Default Block Size
Optimized for large files
Replication Factor
Fault tolerance guarantee
Awareness
Network topology optimization
💡 Performance Tip: For small files, consider using HAR (Hadoop Archive) files or SequenceFiles to reduce NameNode memory pressure and improve processing efficiency.
⚙️YARN Resource Management & Job Scheduling
Yet Another Resource Negotiator (YARN) is Hadoop's cluster resource management system that enables multiple data processing engines to handle data stored in a single platform. Understanding YARN architecture is essential for optimizing resource utilization and job performance.
🎯 Core Components
ResourceManager (RM)
- • Global resource scheduler and arbitrator
- • Manages cluster resources across applications
- • Handles application lifecycle management
- • Provides web UI for monitoring and administration
NodeManager (NM)
- • Per-machine framework agent
- • Manages containers and monitors resource usage
- • Reports node health to ResourceManager
- • Handles container lifecycle operations
📊 Scheduling Strategies
Capacity Scheduler
- • Multi-tenant cluster resource sharing
- • Hierarchical queue management
- • Guaranteed capacity with elasticity
- • Priority-based job scheduling
Fair Scheduler
- • Equal resource distribution by default
- • Preemption for resource fairness
- • Dynamic queue creation
- • User and group-based allocation
🔧 Resource Configuration Best Practices
Memory Management
- • Reserve 20-25% of total RAM for OS and other services
- • Configure yarn.nodemanager.resource.memory-mb appropriately
- • Set container memory limits to prevent OOM errors
- • Use memory overhead settings for JVM-based applications
- • Monitor memory utilization and adjust as needed
CPU Allocation
- • Configure virtual cores based on physical cores
- • Consider hyperthreading in vcore calculations
- • Set appropriate CPU limits for containers
- • Balance CPU and memory ratios for workloads
- • Use CPU isolation for performance-critical jobs
⚡ Optimization Tip: Use YARN's resource profiles and node labels to optimize resource allocation for different workload types and hardware configurations.
🔄Advanced MapReduce Programming Patterns
MapReduce is a programming model for processing large datasets in parallel across distributed clusters. Mastering advanced patterns and optimization techniques is crucial for building efficient big data processing applications.
🎯 Common MapReduce Design Patterns
Filtering & Sampling
- • Filtering: Remove unwanted records based on criteria
- • Bloom Filtering: Probabilistic data structure for membership testing
- • Random Sampling: Extract representative data subsets
- • Top-K: Find the K largest or smallest elements
Aggregation & Summarization
- • Counting: Count occurrences of elements
- • Min/Max: Find minimum and maximum values
- • Average: Calculate mean values with combiners
- • Inverted Index: Create searchable indexes
🚀 Performance Optimization Techniques
Combiner Functions
- • Reduce network I/O by pre-aggregating data
- • Implement associative and commutative operations
- • Use same logic as reducer when possible
- • Monitor combiner effectiveness metrics
Custom Partitioning
- • Ensure balanced data distribution
- • Implement domain-specific partitioning logic
- • Avoid data skew and hotspots
- • Consider secondary sorting requirements
Input/Output Formats
- • Choose appropriate file formats (Avro, Parquet)
- • Implement custom InputFormat for complex data
- • Use compression to reduce I/O overhead
- • Optimize split size for parallel processing
🔗 Advanced Join Patterns
Reduce-Side Join
Standard join pattern where data is shuffled to reducers
- • Suitable for large datasets
- • Handles data skew with proper partitioning
- • Requires sorting and grouping phase
Map-Side Join
Efficient join when one dataset fits in memory
- • No shuffle phase required
- • Faster execution for small lookup tables
- • Uses distributed cache for small datasets
🎯 Best Practice: Always profile your MapReduce jobs using Hadoop's built-in counters and metrics to identify bottlenecks and optimization opportunities.
🌐Hadoop Ecosystem Integration & Data Pipeline Architecture
The Hadoop ecosystem consists of numerous tools and frameworks that work together to provide comprehensive big data processing capabilities. Understanding how to integrate these components is essential for building robust data pipelines.
📊 Data Processing Engines
Apache Spark
- • In-memory computing for faster processing
- • Unified analytics engine for large-scale data
- • Supports batch, streaming, ML, and graph processing
- • 100x faster than MapReduce for iterative algorithms
Apache Hive
- • SQL-like query language (HiveQL) for Hadoop
- • Data warehouse software for reading and managing large datasets
- • Schema-on-read approach for flexible data modeling
- • Integration with BI tools and reporting systems
🔄 Data Ingestion & Movement
Apache Kafka
- • Distributed streaming platform for real-time data
- • High-throughput, low-latency message processing
- • Fault-tolerant storage and replay capabilities
- • Integration with Spark Streaming and Storm
Apache Sqoop
- • Bulk data transfer between Hadoop and RDBMS
- • Incremental imports and exports
- • Parallel data transfer for improved performance
- • Support for various database systems
🏗️ Data Pipeline Architecture Patterns
Lambda Architecture
Combines batch and stream processing for comprehensive data analysis
Kappa Architecture
Stream-first approach using replayable event streams
🔧 Integration Tip: Use Apache Airflow or Oozie for workflow orchestration to manage complex data pipelines with dependencies and scheduling requirements.
🏢Enterprise Deployment & Security Framework
Enterprise Hadoop deployments require robust security, high availability, disaster recovery, and compliance frameworks. This section covers production-grade deployment strategies and security best practices for mission-critical environments.
🔐 Security Architecture
Kerberos Authentication
- • Strong authentication for all cluster services
- • Ticket-based authentication system
- • Integration with Active Directory and LDAP
- • Automatic ticket renewal and management
Apache Ranger
- • Centralized security administration framework
- • Fine-grained access control policies
- • Comprehensive audit and compliance reporting
- • Dynamic security policy updates
🛡️ Data Protection
Encryption at Rest
- • HDFS Transparent Data Encryption (TDE)
- • Key management with Hadoop KMS
- • Per-directory encryption zones
- • Hardware Security Module (HSM) integration
Network Security
- • SSL/TLS encryption for data in transit
- • Network segmentation and firewall rules
- • VPN access for remote administration
- • Intrusion detection and prevention systems
🏗️ High Availability & Disaster Recovery
NameNode HA
- • Active/Standby NameNode configuration
- • Shared storage for edit logs (NFS/QJM)
- • Automatic failover with ZooKeeper
- • Fencing mechanisms for split-brain prevention
ResourceManager HA
- • Multiple ResourceManager instances
- • State store for application recovery
- • Embedded failover and leader election
- • Work-preserving restart capabilities
Backup Strategy
- • Regular metadata backups
- • Cross-datacenter replication
- • Point-in-time recovery procedures
- • Automated backup verification
🚨 Security Alert: Always implement defense-in-depth security strategies with multiple layers of protection, regular security audits, and compliance monitoring.
📈Performance Tuning & Advanced Monitoring
Optimizing Hadoop cluster performance requires understanding of system bottlenecks, resource utilization patterns, and workload characteristics. Comprehensive monitoring and tuning strategies ensure optimal cluster efficiency and user experience.
🎯 Performance Optimization Areas
HDFS Performance
- • Block Size Optimization: Adjust based on file sizes and access patterns
- • Replication Factor: Balance between fault tolerance and storage efficiency
- • DataNode Configuration: Optimize handler threads and transfer settings
- • Network Topology: Configure rack awareness for optimal data placement
- • Compression: Use appropriate codecs for storage and network efficiency
MapReduce Tuning
- • Memory Settings: Configure heap sizes and container memory
- • Parallelism: Optimize number of mappers and reducers
- • I/O Operations: Tune sort buffer and spill thresholds
- • Combiner Usage: Implement combiners to reduce shuffle data
- • Speculative Execution: Enable for handling slow tasks
📊 Monitoring & Alerting Framework
System Metrics
- • CPU, memory, disk, and network utilization
- • JVM heap usage and garbage collection
- • File system capacity and inode usage
- • Network bandwidth and latency
Application Metrics
- • Job execution times and success rates
- • Queue wait times and resource utilization
- • Data processing throughput and latency
- • Error rates and failure patterns
Business Metrics
- • Data freshness and quality indicators
- • SLA compliance and availability metrics
- • Cost per job and resource efficiency
- • User satisfaction and adoption rates
🔧 Troubleshooting Methodology
- 1Identify Symptoms: Gather performance metrics, error logs, and user reports to understand the scope and impact of issues.
- 2Analyze Bottlenecks: Use profiling tools and metrics to identify CPU, memory, I/O, or network constraints affecting performance.
- 3Implement Solutions: Apply targeted optimizations based on root cause analysis, starting with highest-impact changes.
- 4Validate Results: Monitor performance improvements and ensure changes don't introduce new issues or regressions.
📈 Monitoring Stack: Consider using Ambari Metrics, Grafana, Prometheus, and ELK stack for comprehensive cluster monitoring and log analysis.